
Velocity • Durability
Runtime
5 minute read
Audience
AI & HPC leaders, architects, DevOps
Primary themes
Performance · Economics · Simplicity
Think of it as a reliable fleet of high-performance vehicles powering your AI production line: dependable, scalable from compact to heavy-duty models, self-managing failures, and optimized for long-term efficiency, rather than temperamental race cars that demand constant attention.
Throughput Potential
Linear Scalability
Data Durability
Production Deployments
Key Challenges
AI Pipeline Stages & Optimizations
| Stage | Key Requirements | HYDRA Solution |
|---|---|---|
| Data Ingest | High-volume writes, capacity | Parallel ingestion + HDD tiering |
| Model Load / Training | High throughput reads/writes | NVMe flash prioritization + massive parallel I/O |
| Checkpointing | Very high burst writes | Fast parallel writes with linear scaling, MLEC recovery |
| Fine-Tuning / Inference | Low-latency reads, small files | VeLO for billions ops/sec, flash acceleration |
| Archive / Retention | Cost-efficient capacity | HDD expansion + intelligent data placement |
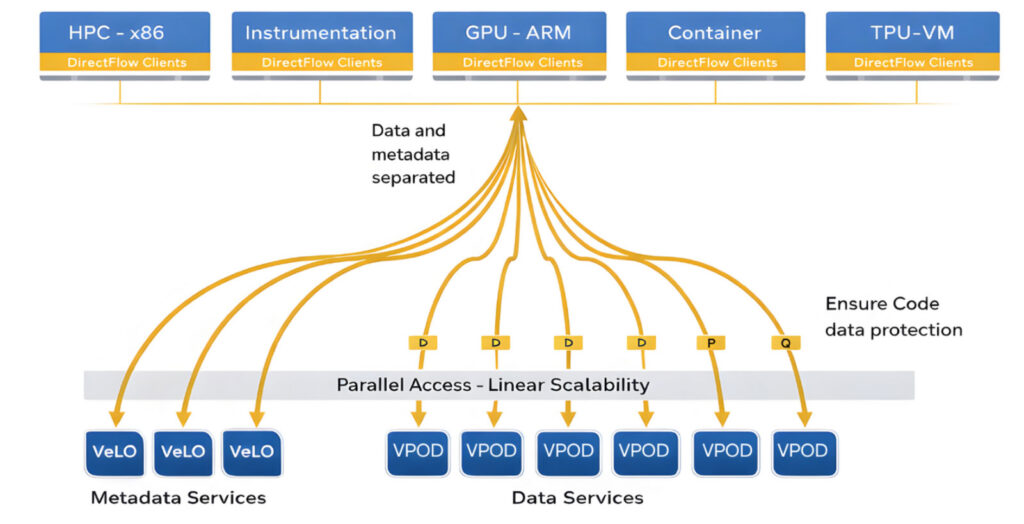
Shared-Nothing Architecture
For AI factories, this means infrastructure that scales economically and predictably: add commodity nodes as needed, let HYDRA deliver consistent performance and handle failures transparently, and focus your resources on training models, not managing storage hardware.
The VDURA Advantage
Platform Capabilities at a Glance
| Capability | Specification |
|---|---|
| Throughput | Terabytes/sec potential with linear scaling |
| Scalability | Exabytes capacity, thousands of nodes per cluster |
| Durability | Up to 12 nines (all-flash), 11 nines (hybrid) |
| Availability | Six nines+ in production environments |
| Media Support | NVMe SSD (TLC/QLC) + SATA HDD (CMR/SMR/HAMR) |
| Protocols | POSIX/DirectFlow, NFS, SMB, S3, CSI |
| Encryption | AES-256 end-to-end, KMIP key management |
| Metadata | VeLO: billions of INODE operations/sec |
| Self-Healing | Automated recovery, scrubbing, balancing |
| Deployment | 1,000+ production deployments worldwide |
VDURA’s HYDRA architecture carries decades of production-proven maturity from PanFS’s 25+ year legacy, trusted across thousands of deployments in the world’s most demanding environments including leading research labs, service providers, government institutions, and Fortune 500 enterprises. These systems have accumulated tens of millions of cumulative runtime hours in live production clusters.
Download the full VDURA Data Platform V11 White Paper or visit vdura.com for a tailored AI factory assessment.